In this post, I will introduce some of the ideas underlying sample size planning for precision. The ideas are illustrated with a shiny-application which can be found here: https://gmulder.shinyapps.io/PlanningApp/. The app illustrates the basic theory considering sample size planning for two independent groups. (If the app is no longer available (my allotted active monthly hours are limited on shinyapps.io), contact me and I’ll send you the code).
The basic idea is that we are planning an experiment to estimate the difference in population means of an experimental and a control group. We want to know how many observations per group we have to make in order to estimate the difference between the means with a given target precision.
Our measure of precision is the Margin of Error (MOE). In the app, we specify our target MOE as a fraction (f) of the population standard deviation. However, we do not only specify our target MOE, but also our desired level of assurance. The assurance is the probability that our obtained MOE will not exceed our target MOE. Thus, if the assurance is .80 and our target MOE is f = .50, we have a probability of 80% that our obtained MOE will not exceed f = .50.
The only part of the app you need for sample size planning is the “Sample size planning”-form. Specify f, and the assurance, and the app will give you the desired sample size.
If you do that with the default values f = .50 and Assurance = .80, the app will give you the following results on the Planning Results-tab: Sample Size: 36.2175, Expected MOE (f): 0.46. This tells you that you need to sample 37 participants (for instance) per group and then the Expected MOE (the MOE you will get on average) will equal 0.46 (or even a little less, since you sample more than 36.2175 participants).
The Planning-Results-tab also gives you a figure for the power of the t-test, testing the NHST nil-hypothesis for the effect size (Cohen’s d) specified in the “Set population values”-form. Note that this form, like the rest of the app provides details that are not necessary for sample size planning for precision, but make the theoretical concepts clear. So, let’s turn to those details.
Even though it is not at all necessary to specify the population values in detail, considering the population helps to realize the following. The sample size calculations and the figures for expected MOE and power, are based on the assumption that we are dealing with random samples from normal populations with equal variances (standard deviations).
From these three assumptions, all the results follow deductively. The following is important to realize:
if these assumptions do not obtain, the truth of the (statistical) conclusions we derive by deduction is no longer guaranteed. (Maybe you have never before realized that sample size planning involves deductive reasoning; deductive reasoning is also required for the calculation of p-values and to prove that 95% confidence intervals contain the value of the population parameter in 95% of the cases; without these assumptions is it uncertain what the true p-value is and whether or not the 95% confidence interval is in fact a 95% confidence interval).
In general, then, you should try to show (to others, if not to yourself) that it is reasonable to assume normally distributed populations, with equal variances and random sampling, before you decide that the p-value of your t-test, the width of your confidence interval, and the results of sample size calculations are believable.
The populations in the app are normal distributions. By default, the app shows two such distributions. One of the distributions, the one I like to think about as corresponding to the control condition, has μ = 0, the other one has μ = 0.5. Both distributions have a standard deviation (σ = 1). The standardized difference between the means is therefore equal to δ = 0.50.
The default populations are presented in Figure 1 below.
 |
| Figure 1: Two normal distributions. The distribution to the left has μ = 0, the one to the right has μ = 0.5 The standard deviation in both distributions equals σ = 1. The standardized difference δ and the unstandardized difference between the means both equal 0.50. |
The sampling distribution of the mean difference
The other default setting in the app is a sample size (per group) of n = 20. From the sample size and the specification of the populations, we can deduce the probability density of the different values of the estimates of the difference between the population means. The estimate is simply the difference between the sample means.
This so-called sampling distribution of the mean difference is depicted on the tab next to the population. Figure 2 shows what the sampling distribution looks like if we repeatedly draw random samples of size n = 20 per group from our populations and keep track of the difference between the sample means we get in each repetition.
 |
| Figure 2: Sampling distribution of the difference between two sample means based on samples of n = 20 per group and random sampling from the populations described in Figure 1. |
Note that the mean of the sampling distribution equals 0.5 (as indicated by the middle vertical line). This is of course the (default) difference between the population means in the app. So, on average, estimates of the population difference equal the population difference.
The lines to the left and the right of the mean indicate the mean plus or minus the Margin of Error (MOE). The values corresponding to the lines are 0.5 ± MOE. 95% of estimates of the population mean difference have a value between these lines.
Conceptually, the purpose of planning for precision is to decrease the (horizontal) distance between these lines and the population mean difference. In other words, we would like the left and right lines as close to the mean of the distribution as is practically acceptable and possible.
The distribution of the t-statistic
The tab next to the sampling distribution tab contains a figure representing the sampling distribution of the t-statistic. The sampling distribution of t can be deduced on the basis of the population values and the sample size. In the app, it is assumed that t is calculated under the assumption that the null-hypothesis of zero difference between the means is true. The sampling distribution of t is what you get if you repeatedly sample from the populations as specified, calculate the t-statistic and keep a record of the values of the t-statistic.
The sampling distribution of the t-statistic presented in Figure 3 contains two vertical lines. These lines are located (horizontally) on the value of t that would lead to rejection of the null-hypothesis of equal population means. In other words, the lines are located at the critical value of t (for a two-tailed test).
 |
| Figure 3: Distribution of the t-statistic testing the null-hypothesis of equal population means. The distribution is based on sampling from the populations described in Figure 3. The sample size is n = 20 per group. The lines represent the critical value of t for a two sided t-test. The area between the vertical lines is the probability of a type II error. The combined areas to the left of the left line and to the right of the right line is the power of the test. |
The area between the lines is the probability that the null-hypothesis will not be rejected. In the case of a true population mean difference (which is the default assumption in the app), that probability is the probability of an error of the second kind: a type II error.
The complement of that probability is called the power of the test. This is, of course, the area to the left of the left vertical line added to the area to the right of the right vertical line. Conceptually, the power of the test is the probability of rejecting the null-hypothesis when in fact it is false.
Figure 3 clearly demonstrates that if the true mean difference equals 0.50 and the sample size (per group) equals n = 20, that there is a large probability that the null-hypothesis will not be rejected. Actually, the probability of a type II error equals .66. (So, the power of the test is .34).
Sample size planning for precision
With respect to sample size planning for precision, the app by default takes half of a standard deviation (f = .50) as the target MOE. Besides, planning is with 80% assurance. This means that the default settings search for a sample size (per group), so that with 80% probability MOE will not exceed 0.50 (Note that the default value of the standard deviation is 1, so an f of .50 corresponds to a target MOE of 0.50 on the scale of the data; Likewise, were the standard deviation equal to 2, an f of .50 would correspond to a target MOE of 1.0).
As described above, planning with the default values gives us a sample size of n = 37 per group, with an expected MOE of 0.46. In the tab next to the planning results, a figure displays what you can expect to find on average, given the planned sample size and the specification of the population. That figure is repeated here as Figure 4.
 |
| Figure 4: Expected results in terms of point and interval estimates (95% confidence intervals). This is what you will find on average given the population specification in Figure 1 and using the default values for sample size planning. |
Figure 4 displays point and interval estimates of the group means and the difference between the means. The interval estimates are 95% confidence intervals. The figure clearly shows that on average, our estimate of the difference is very imprecise. That is, the expected 95% confidence interval ranges from almost 0 (0.50 – 0.46 = 0.04) to almost 1 (0.50 + 0.46 = 0.96). Of course, using n = 20, would be worse still.
A nice thing about the app (well, I for one think it’s pretty cool) is that as soon as you ask for the sample sizes, the sample size in the set population values form is automatically updated. Most importantly, this will also update the sampling distribution graphs of the difference between the means and the t-statistic. So, it provides an excellent way of showing what the updated sample size means in terms of MOE and the power of the t-test.
Let’s have a look at the sampling distribution of the mean difference, see Figure 5.
 |
| Figure 5: Sampling distribution of the mean difference with n = 37 per group. Compare with Figure 2 to see the (small) difference in the Margin of Error compared to n = 20. |
If you compare Figures 5 and 2, you see that the vertical lines corresponding to the mean plus and minus MOE have shifted somewhat towards the mean. So here you can see, that almost doubling the sample size (from 20 to 37) had the desired effect of making MOE smaller.
I would like to point out the similarity between the sampling distribution of the difference and the expected results plot in Figure 4. If you look at the expected results for our estimate of the population difference, you see that the point estimate corresponds to the mean of the sampling distribution, which is of course equal to the populations mean difference and that the limits of the expected confidence interval correspond to the left and right vertical lines in Figure 5. Thus, on average the limits of the confidence interval correspond to the values that mark the middle 95% of the sampling distribution of the samples mean difference.
Since we specified an assurance of 80%, there is an 80% probability that in repeated sampling from the populations (see Figure 1) with n = 37 per group, our (estimated) MOE will not exceed half a standard deviation. Thus, whatever the true value of the populations mean difference is, there is a high probability that our estimate will not be more than half a standard deviation away from the mean. This is, I think, one of the major advantages of sample size planning for precision: we do not have to specify the unknown population mean difference. This is in contrast to sample size planning for power, where we do have to specify a specific population mean difference.
Speaking of power, the results of the sample size planning suggest that for our specification of the populations mean difference (Cohen’s delta = 0.50) the power of the test equals 0.56. Thus, there is a probability of 56% that with n = 37 per group the t-test will reject. The probability of a type II error is therefore 44%.
Figure 6 shows the distribution of the t statistic with n = 37 per group and a standardized effect size of 0.50.
 |
| Figure 6. The distribution of the t-statistic testing the null-hypothesis of equal population means. The distribution is based on the population specification in Figure 1 and sample sizes of n = 37 per group, with true effect size equal to 0.50. The probability of a type II error is the area of under the curve between the two vertical lines. The power is the area under the curve beyond the two lines. Compare with Figure 3 to see the differences in these probabilities compared to n = 20. |
Power versus precision
Now suppose that the unstandardized mean difference between the population means equals 2 and that the standard deviation equals 2.5. I just filled in the set population values form, setting the mean of population 2 to 2.0 and the standard deviation to 2.5. And I clicked set values.
Let us plan for a target MOE of f = 0.5 standard deviations with 80% assurance. Click get sample sizes in the sample size planning form. In this case, target MOE equals 1.25.
The results are not very surprising. Since the f did not change compared to the previous time, the results as regards the sample size are exactly the same. We need n = 37. Again, this is what I like about sample size planning, no matter what the unknown situation in the population is, I just want my margin of error to be no more than half a standard deviation (for example).
But the power did change (of course). Since the standardized population mean difference is now 0.80 (= 2.0 / 2.5) in stead of 0.50, and all the other specifications remained the same, the power increases from 56% to 92%. That’s great.
However, the high probability of rejecting the null-hypothesis does not mean that we get precise estimates. On average, the point estimate of the difference equals 2 and the 95% confidence limits are 0.85 and 3.15 (the point estimate plus or minus 0.46 times the standard deviation of 2.5). See Figure 7.
 |
| Figure 7: Expected results using n = 37 when sampling from two normal populations with equal standard deviations (σ = 2.5) and mean difference of 2.0. The standardized effect size equals 0.80. Note the imprecision of the estimates even though the power of the t-test equals .92. |
In short, even though there is a high probability of (correctly) rejecting the null-hypothesis of equal population means, we are still not in the position to confidently conclude what the size of the difference is: the expected confidence interval is very wide.




















 . Now, suppose that due to some freak accident of nature there are no differences in the mean scores (averaged of stimuli) of each participant. In that case,
. Now, suppose that due to some freak accident of nature there are no differences in the mean scores (averaged of stimuli) of each participant. In that case,  . This means that under these circumstances the expected mean square associated with participants is simply an estimate of the error variance with
. This means that under these circumstances the expected mean square associated with participants is simply an estimate of the error variance with  degrees of freedom, because
degrees of freedom, because  , if
, if  degrees of freedom. The logic of the F-test is that under the null-hypothesis, in our case that
degrees of freedom. The logic of the F-test is that under the null-hypothesis, in our case that  . If we now suppose that there is no difference between the treatment means, that is
. If we now suppose that there is no difference between the treatment means, that is  , MSTreatment does not estimate
, MSTreatment does not estimate  , but
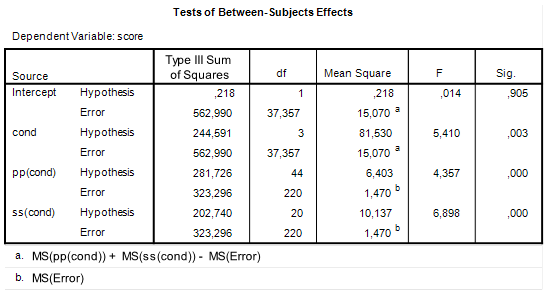
, but  . Note that no other source of variance has an expected mean square that is equal to the latter figure. That is, in contrast to our test of the Participant factor, where under the null-hypotheses two Mean Squares estimate the error variance, i.e. MSParticipant and MSError, no mean square is available to form an F-ratio to test the Treatment effect.
. Note that no other source of variance has an expected mean square that is equal to the latter figure. That is, in contrast to our test of the Participant factor, where under the null-hypotheses two Mean Squares estimate the error variance, i.e. MSParticipant and MSError, no mean square is available to form an F-ratio to test the Treatment effect.![[m\sigma^2_p + \sigma^2_e] + [m\sigma^2_s + \sigma^2_e] - [\sigma^2_e] = m\sigma^2_p + n\sigma^2_s + \sigma^2_e](https://small-s.science/wp-content/ql-cache/quicklatex.com-9cd6bb15506816413e74641fee23cf13_l3.png "Rendered by QuickLaTeX.com") . It is exactly this linear combination of mean squares that is used in the F-ratio to obtain an error term against which to test the Treatment effect in Figure 1:
. It is exactly this linear combination of mean squares that is used in the F-ratio to obtain an error term against which to test the Treatment effect in Figure 1:  . We will also use this figure to obtain the variance (and standard error) of our contrast estimate.
. We will also use this figure to obtain the variance (and standard error) of our contrast estimate.![\[df=\frac{(MSp+MSs-MSe)^{2}}{\frac{MSp^{2}}{df_{p}}+\frac{MSs^{2}}{df_{s}}+\frac{MSe^{2}}{df_{e}}}.\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-13f753be88a6e13890953c2465e22a05_l3.png "Rendered by QuickLaTeX.com")
 can be obtained as follows.
can be obtained as follows.![\[\hat{\sigma}_{\hat{\psi}}=\sqrt{\sum c_{i}^{2}\hat{\sigma}_{\bar{X},Rel}^{2}},\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-489e315828278a9811848f3ce71bf10f_l3.png "Rendered by QuickLaTeX.com")
 to refer to the relative error variance of the treatment mean (which in this design is equal to the absolute error variance, but that’s another story), and
to refer to the relative error variance of the treatment mean (which in this design is equal to the absolute error variance, but that’s another story), and  refers to the contrast weight of treatment mean i. The relative error variance of the treatment mean is obtained by dividing the error variance that is used to test the treatment effect by the total number of observations in each treament,
refers to the contrast weight of treatment mean i. The relative error variance of the treatment mean is obtained by dividing the error variance that is used to test the treatment effect by the total number of observations in each treament,  . Thus, using the results in Figure 1.
. Thus, using the results in Figure 1.![\[\hat{\sigma}_{\bar{X},Rel}^{2}=\frac{MS_{p}+MS_{s}-MS_{e}}{nm}=\frac{15.07}{72}=0.2093.\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-0d81fe2ec65ea2c26c84682713e499bf_l3.png "Rendered by QuickLaTeX.com")
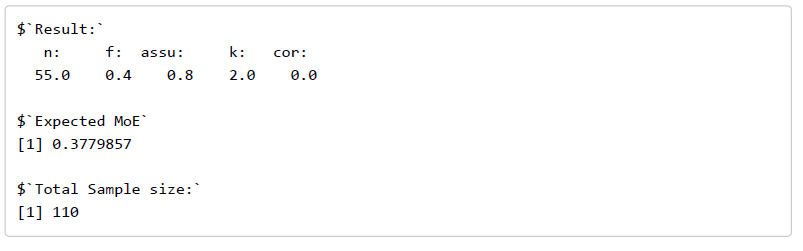
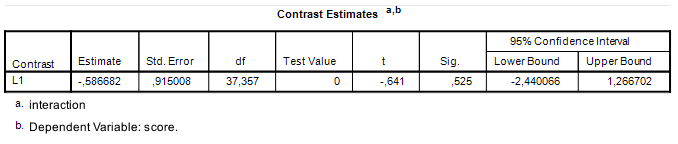
 . Let’s use the results in Figure 1 to calculate what MOE is for this particular contrast.
. Let’s use the results in Figure 1 to calculate what MOE is for this particular contrast. , with 220 degrees of freedom and not
, with 220 degrees of freedom and not  , with 37.357 (see Figure 1). The consequence of this is, of course, that the 95% CI is much narrower than it should be.
, with 37.357 (see Figure 1). The consequence of this is, of course, that the 95% CI is much narrower than it should be. , the critical value of t is the .975 quantile of the central t distribution with
, the critical value of t is the .975 quantile of the central t distribution with  , which equals
, which equals  . The value of MOE is therefore
. The value of MOE is therefore  . With a contrast estimate of
. With a contrast estimate of  , the 95% CI equals
, the 95% CI equals ![-0.587 \pm 0.5633 = [-1.1503, -0.0237]](https://small-s.science/wp-content/ql-cache/quicklatex.com-ea5612615f1baf096374644a223d775f_l3.png "Rendered by QuickLaTeX.com") . In comparison, using the correct value of MOE gives us
. In comparison, using the correct value of MOE gives us ![[−2.4404, 1.2664]](https://small-s.science/wp-content/ql-cache/quicklatex.com-ef97651e8790dc304790e8a8724ebed7_l3.png "Rendered by QuickLaTeX.com") .
.
 , approximate 95% CI
, approximate 95% CI ![[-1.40, 0.73]](https://small-s.science/wp-content/ql-cache/quicklatex.com-867264624a612f401b2c1cea536372a9_l3.png "Rendered by QuickLaTeX.com") , which according to the rules of thumb is a medium negative effect, but consistent with anytihing from a huge negative effect to a large positive effect in the population, as the approximate CI shows. (I have divided the point estimate and the confidence interval in Figure 2 by 1.74, to obtain Cohen’s d and an approximate confidence interval). Clearly, then, our precision can be optimized.
, which according to the rules of thumb is a medium negative effect, but consistent with anytihing from a huge negative effect to a large positive effect in the population, as the approximate CI shows. (I have divided the point estimate and the confidence interval in Figure 2 by 1.74, to obtain Cohen’s d and an approximate confidence interval). Clearly, then, our precision can be optimized. , the stimulus variance
, the stimulus variance  , and the error variance
, and the error variance  . Rearranging and using 1.47 as an estimate for
. Rearranging and using 1.47 as an estimate for  . Likewise, the estimate for
. Likewise, the estimate for  . Thus, our estimates are
. Thus, our estimates are  ,
,  , and
, and  .
.
 , for assurance the value .80 and the values
, for assurance the value .80 and the values  , and
, and  for, respectively, Residual variance, Participant intercept variance and Stimulus intercept variance. Fill in the value 0 for all the other variances. See Figure 5.
for, respectively, Residual variance, Participant intercept variance and Stimulus intercept variance. Fill in the value 0 for all the other variances. See Figure 5.


 , to refer to the residual variance in the BwC-design, we can say
, to refer to the residual variance in the BwC-design, we can say  . Normally, the precision app sums these two components to get a value for the residual variance in the BwC-design, and you will obviously get the same result if you specify the residual variance as the sum and the participant-by-stimulus variance as 0. Likewise,
. Normally, the precision app sums these two components to get a value for the residual variance in the BwC-design, and you will obviously get the same result if you specify the residual variance as the sum and the participant-by-stimulus variance as 0. Likewise,  , and
, and  , where
, where  and
and  are the variances associated with the interaction of treatment and participant and treatment and stimulus, respectively.
are the variances associated with the interaction of treatment and participant and treatment and stimulus, respectively. , and there is 80% assurance that MOE will not exceed
, and there is 80% assurance that MOE will not exceed  . Note, again, that the assurance MOE is somewhat larger than target MOE, because a sample of 804 participants requires a sample of more than 500 stimuli to get the target MOE with 80% assurance and 500 stimuli is the maximum number of stimuli the app considers when minimizing the number of participants.
. Note, again, that the assurance MOE is somewhat larger than target MOE, because a sample of 804 participants requires a sample of more than 500 stimuli to get the target MOE with 80% assurance and 500 stimuli is the maximum number of stimuli the app considers when minimizing the number of participants.

 ,
,  ,
,  ,
,  ,
,  , and
, and  . The Satterthwaite degrees of freedom are
. The Satterthwaite degrees of freedom are  . The standard error of the contrast equals
. The standard error of the contrast equals  . The critical value for t equals
. The critical value for t equals  . Expected MOE is, therefore,
. Expected MOE is, therefore,  (the tiny difference with the results from the app is due to rounding errors).
(the tiny difference with the results from the app is due to rounding errors). -distribution. That is, we assume with assurance
-distribution. That is, we assume with assurance  , that the
, that the  . Now, the degrees of freedom are
. Now, the degrees of freedom are  , the assurance
, the assurance  , and the .80 quantile of
, and the .80 quantile of  . Since the relative error variance equals
. Since the relative error variance equals  , the .80 quantile of the error variance equals
, the .80 quantile of the error variance equals  . And this means that assurance MOE equals
. And this means that assurance MOE equals  . Again, the difference with the results from the Precision App are due to rounding error.
. Again, the difference with the results from the Precision App are due to rounding error. of the simple linear regression equation
of the simple linear regression equation  . The basic ingredients we need for sample size planning are a measure of the precision, a way to determine the quantiles of the sampling distribution of our measure of precision, and a way to calculate sample sizes.
. The basic ingredients we need for sample size planning are a measure of the precision, a way to determine the quantiles of the sampling distribution of our measure of precision, and a way to calculate sample sizes. , where
, where  , is the .975 quantile of the central t-distribution with
, is the .975 quantile of the central t-distribution with  degrees of freedom, and
degrees of freedom, and  is the standard error of the estimate of
is the standard error of the estimate of  (Wilcox, 2017): the variance of Y given X divided by the sum of squared errors of X. The variance
(Wilcox, 2017): the variance of Y given X divided by the sum of squared errors of X. The variance  equals
equals  , the variance of Y multiplied by 1 minus the squared population correlation between Y and X, and it is estimated with the residual variance
, the variance of Y multiplied by 1 minus the squared population correlation between Y and X, and it is estimated with the residual variance  , where
, where  .
.![\[\hat{\sigma}_{\hat{\beta_{1}}}^{2}=\frac{\sum(Y-\hat{Y})^{2}/df_{e}}{\sum(X-\bar{X})^{2}}. \]](https://small-s.science/wp-content/ql-cache/quicklatex.com-712f2857df79a9cc19ad5198431f2877_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\sum(Y-\hat{Y})^{2}}{\sigma_{y}^{2}(1-\rho^{2})}\sim\chi^{2}(df_{e}),\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-5fb82f0623b2088e7771fbf7e7d4803c_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\sum(Y-\hat{Y})^{2}}{df_{e}}\sim\frac{\sigma_{y}^{2}(1-\rho^{2})\chi^{2}(df_{e})}{df_{e}}.\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-6f1e262a579b65243e1854e59a4243d6_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\sum(X-\bar{X})^{2}}{\sigma_{X}^{2}}\sim\chi^{2}(df),\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-fe2f47a4c99a2963559b96659fb59616_l3.png "Rendered by QuickLaTeX.com")
 , therefore
, therefore![\[\sum(X-\bar{X})^{2}\sim\sigma_{X}^{2}\chi^{2}(df).\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-e793ae0023912bb5ee2c4d42856eb6a8_l3.png "Rendered by QuickLaTeX.com")
 , and multiplying by 1 (
, and multiplying by 1 ( ).
).![\[df\sigma_{X}^{2}\sim df\sigma_{X}^{2}\chi^{2}(df)/df.\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-0f86831fd6d9113dcff83251b70eb992_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\sigma}_{\hat{\beta_{1}}}^{2}\sim\frac{\sigma_{y}^{2}(1-\rho^{2})\chi^{2}(df_{e})/df_{e}}{df\sigma_{X}^{2}\chi^{2}(df)/df}=\frac{\sigma_{y}^{2}(1-\rho^{2})}{df\sigma_{X}^{2}}\frac{\chi^{2}(df_{e})/df_{e}}{\chi^{2}(df)/df}=\frac{\sigma_{y}^{2}(1-\rho^{2})F(df_{e,}df)}{df\sigma_{X}^{2}},\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-cdc57f8bf40a827845ec2f30dcfb8751_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{MOE}\sim t_{.975}(N-2)\sqrt{\frac{\sigma_{y}^{2}(1-\rho^{2})F(N-2,N-1)}{(N-1)\sigma_{X}^{2}}}. \]](https://small-s.science/wp-content/ql-cache/quicklatex.com-f0b396b6b94f61a97099bec31546363b_l3.png "Rendered by QuickLaTeX.com")
 ,
,  ,
,  ,
,  , and assurance is .80, then according to (2), 80% of estimated MOEs will not exceed the value given by:
, and assurance is .80, then according to (2), 80% of estimated MOEs will not exceed the value given by: