Suppose you want to do a chi-square test for independence in jamovi, but you only have summary data. Fortunately it is super easy to do that in jamovi. Here is how.
This example is based on a question from an assignment I use in my Applied Statistics course (the assignment itself is from the instructor resources of the book Introduction to the New Statistics (first edition)).
The introductory text to the question is as follows.
To what extent might feeling powerful make you less considerate of the perspective of others? In one study (Galinsky et al., 2006), participants were manipulated to feel either powerful (High Power) or powerless (Low Power). They were then asked to write an ‘E’ on their forehead with a washable marker. Those who wrote the ‘E’ to be correctly readable from their own perspective—looking from inside the head—were considered ego-centric (Ego); those who wrote it to be readable to others were considered to be non-ego-centric (Non-Ego).
Table 1 contains the data of the original study.
Ego
Non-Ego
Total
High Power
8
16
24
Low Power
4
29
33
Total
12
45
57
Table 1. Contingency table with the original data
Creating the dataset using summary data in jamovi
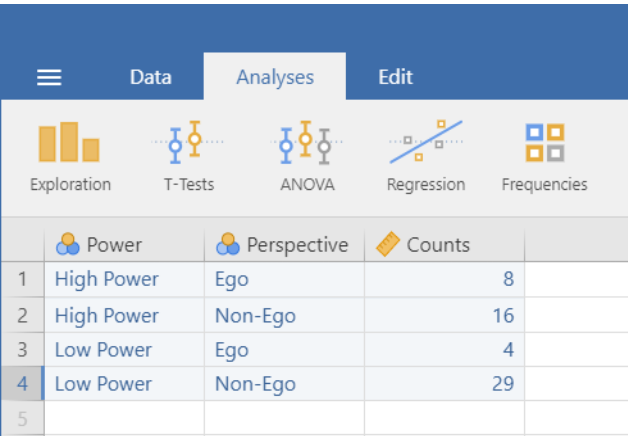
All you need to do is to a create a dataset with three variables. The first two variables are nominal variables. These variable define the rows and columns of your contingency table. Here, I opted for the variables Power, with levels 1 = High Power and 2 = Low Power and Perspective, with levels 1 = Ego and 2 = Non-Ego.
The third variable is the variable Counts (which can be nominal, ordinal and continuous, a far as I can tell). The count variable contains the number of observations for each combination of the two categorical variables.
This is what the dataset looks like:
Figure 1. Jamovi dataset containing summary data for the chi-square test.
Doing the chi-square test
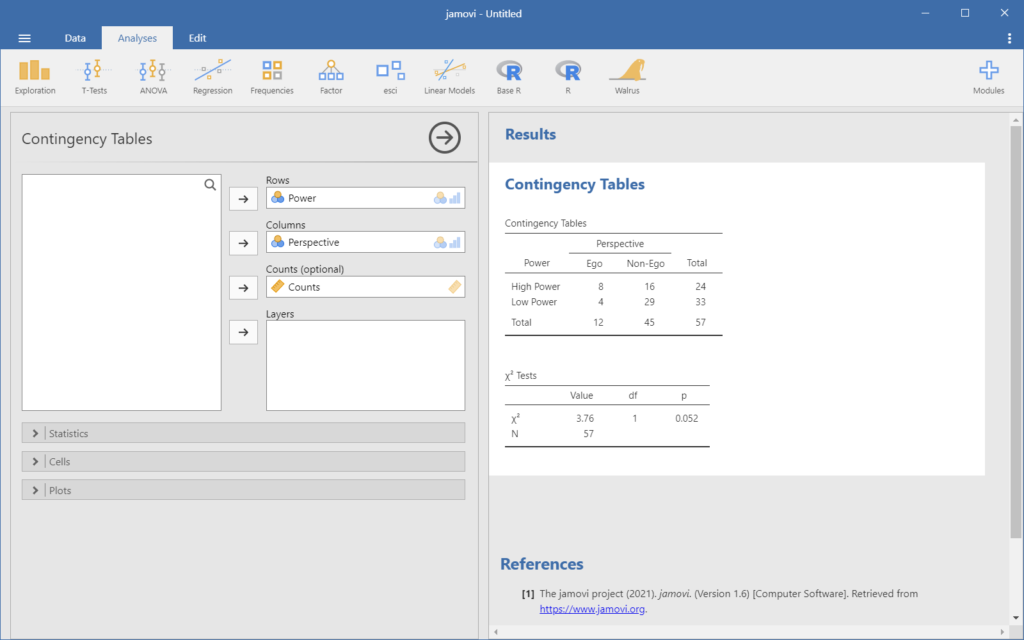
If you have the dataset, the rest is super easy as well. Just choose Frequencies on the Analyses tab followed by Independent samples. Now place your row, columns and counts variables in the right spot, as in Figure 2. That’s all!
Figure 2. input and output of the chi-square test using summary data in jamovi.
Comparing the quantiles of two groups provides information that is lost by simply looking at means or medians. This post shows how to do that.
Traditionally, the comparison of two groups focuses on comparing means or medians. But, as Wilcox (2012) explains, there are many more features of the distributions of two groups that we may compare in order to shed light on how the groups differ. An interesting approach is to estimate the difference between the quantiles of the two groups. Wilcox (2012, pp. 138-150) shows us an approach that is based on the shift function. The procedure boils down to estimating the quantiles of both groups, and plotting the quantiles of the first group against the difference between the quantiles.
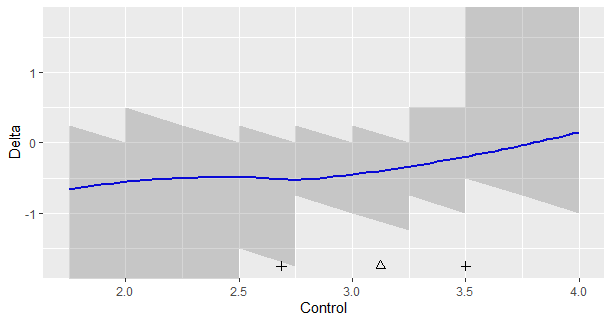
Let’s look at an example. Figure 1 presents data from an experiment investigating the persuasive effect of narratives on intentions of adopting a healthy lifestyle (see for details Boeijinga, Hoeken, and Sanders (2017)). The plotted data are the differences in intention between the quantiles of a group of participants who read a narrative focusing on risk-perception (detailing the risks of unhealthy behavior) and a group of participants who read a narrative focusing on action-planning (here called the control group), focusing on how the healthy behavior may actually be implemented by the participant.
Figure 1. Output from the plotSband-function
Figure 1 shows the following. The triangle is the median of the data in the control group, and the plusses the .25th and .75th quantiles. The shaded regions define the simultaneous 95% confidence intervals for the differences between the quantiles of the two groups. Here, these regions appear quite ragged, because of the discrete nature of the data. For values below 2.5 and above 3.5, the limits (respectively the lower and upper limits of the 95% CI’S) equal infinity, so these values extend beyond the limits of the y-axis. (The sband function returns NA for these limits). The smoothed-regression line should help interpret the general trend.
How can we interpret Figure 1? First of all, if you think that it is important to look at statistical significance, note that none of the 95% intervals exclude zero, so none of the differences reach the traditional significance at the .05 level. As we can see, none of them exclude differences as large as -0.50 as well, so we should not be tempted to conclude that because zero is in the interval that we should adopt zero as the point-estimate. For instance, if we look at x = 2.5, we see that the 95% CI equlas [-1.5, 0.0], the value zero is included interval, but so is the value -1.5. It would be unlogical to conclude that zero is our best estimate if so many values are included in the interval.
The loess-regression line suggests that the differences in quantiles between the two groups of the narrative is relatively steady for the lower quantiles of the distribution (up to the x = 3.0, or so; or at least below the median), but for quantiles larger than the median the effect gets smaller and smaller until the regression line crosses zero at the value x = 3.75. This value is approximately the .88 quantile of the distribution of the scores in the control condition (this is not shown in the graph).
The values on the y-axis are the differences between the quantiles. A negative delta means that the quantile of the control condition has a larger value than the corresponding quantile in the experimental condition. The results therefore suggest that participants in the control condition with a relatively low intention score, would have scored even lower in the other condition. To give some perspective: expressed in the number of standard deviations of the intention scores in the control group a delta of -0.50 corresponds to a 0.8 SD difference.
Note however, that due to the limited number of observations in the experiment, the uncertainty about the direction of the effect is very large, especially in the tails of the distribution (roughly below the .25 and above the .75 quantile). So, even though the data suggest that Action Planning leads to more positive intentions, especially for the lower quantiles, but still considerably for the .75 quantile, a (much) larger dataset is needed to obtain more convincing evidence for this pattern.