I’ve created a first version of Shiny App for sample size planning for precise contrast estimates in one and two-way designs. So, if you want to plan for interaction contrasts for two-way designs, take a look here: https://gmulder.shinyapps.io/PlanningFactorialContrasts/
Important: this is a first version that contains no error checking (but you know what you’re doing, so that’s not a problem). Also, I have not tested the results of the app with simulation studies. As soon as I have done that, I will share the code of the app.
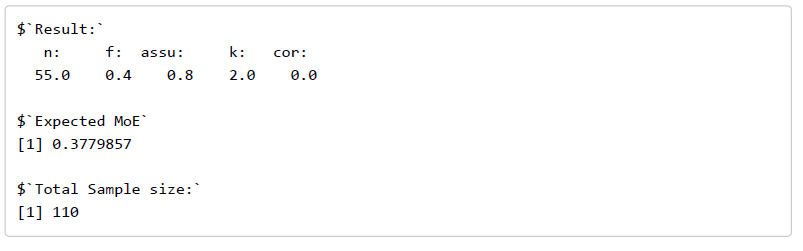
Update: The values for the factorial two-way within subjects designs are checked with simulation studies (for f = .40, assurance = .80, and correlation rho = .50).
Note: if you have a single factor design, you may also consider looking here: http://small-s.science/?p=19
Note: if you have a two-groups independent design, go here for an introduction to sample size planning and its relation to the power of the t-test: http://small-s.science/?p=25
See for more detailed information about sample size planning for single factor and factorial designs (between, within, and mixed): http://small-s.science/?p=10 and for guidelines for setting target MoE: http://small-s.science/?p=14)
How does the app work?
1. Specifying Target MoE and Assurance
Target MoE should be specified in a number of standard deviations (usually a fraction; for details see Cumming, 2012;
Cumming & Calin-Jageman, 2017). The symbol f will be used to refer to this standardized MoE. Target MoE (f) must be larger than zero (f will be automatically set to .05 if you accidentally fill in the value 0).
I suggest using the following guidelines for target MoE (f):
| Description |
f |
| Extremely Precise |
.05 |
| Very Precise |
.10 |
| Precise |
.25 |
| Reasonably Precise |
.40 |
| Borderline Precise |
.65 |
You should only use these guidelines if you lack the information you need for specifying a reasonable value for Target MoE.
Assurance is the probability that (to be) obtained MoE will be no larger than Target MoE. I suggest setting Assurance minimally at .80.
Assumptions of the App
The app uses the within condition standard deviation as the standardizer for MoE. For the factorial designs this is the variance within each combination of the factor levels. The app assumes equal variances and, for the mixed and within subject designs equal covariances as well.
2. Specifying number of factors, design, correlation and levels of each factor
You can plan for designs with one factor (between and within designs) and two factors (between, within, and mixed designs).
If you have a mixed design, the first factor (Factor A) is considered to be the between subjects factor and the second factor (Factor B) the within subjects factor.
The app also requires a value for the cross-condition correlation in the within or mixed designs.
3. Specifying contrasts
Main comparisons
The default contrasts for main comparisons are Helmert contrasts, but you can specify any contrast you like. Use commas to separate the contrast weights and use semi-colons to separate the weights of different contrasts. For example, the “1, -1/2, -1/2; 0, 1, -1” indicates two contrasts, the first contrast has weights {1, -1/2, -1/2}, the second contrast has weights {0, 1, -1}.
It is recommended that the absolute values of the contrast weights of each contrast sum to 2.0 (except for interaction contrasts, where the absolute values should sum to 4.0).
You will only have to specify contrasts for the marginal means of each factor. The app calculates appropriate values for the contrast weights of each cell in the design based on the weights for the marginal means. For example, in a 2×2 design the weights for the marginal means for each factor may be {1, -1]. The app translates this to {0.5, 0.5, -0.5, -0.5}, to account for the fact that the contrast etimates involves the combination of each of the 2×2 cell means.
Interaction contrasts
The app calculates the interaction contrasts on the basis of the contrasts specified for the main comparisons. So, if you want to plan for your favorite interaction, simply type in the weights for the two main comparisons involved. Suppose you have a 2×2 design, for example, and you want to plan for an interaction contrasts with weigths {1, -1, -1, 1}, type in “1, -1” for factor A and “1, -1” for factor B.
As another example, suppose factor A has two levels and factor B has three, and you want to estimate the extent to which the difference between the first level of B and the means of the other two levels differes between the levels of A. You type in “1, -1” for factor A, and “1, -1/2, -1/2” for factor B, and the app will calculate the interaction contrast with weights {1, -1/2, -1/2, -1, 1/2, 1/2}.
After planning the results: you can check whether the contrasts are what you intended by looking at the “Contrast Summary” output-tab.
4. Output
The output contains sample sizes per treatment (combination) and total samples required for target MoE and assurance. You will get samples sizes per contrast.
On the “Contrasts Summary” tab the app shows information about the contrast weights.