
Planning for precision requires that we choose a target Margin of Error (MoE; see this post for an introduction to the basic concepts) and a value for assurance, the probability that MoE will not exceed our target MoE. What your exact target MoE will be depends on your research goals, of course.
Cumming and Calin-Jageman (2017, p. 277) propose a strategy for determining target MoE. You can use this strategy if your research goal is to provide strong evidence that the effect size is non-zero. The strategy is to divide the expected value of the difference by two, and to use that result as your target MoE.
Let’s restrict our attention to the comparison of two means. If the expected difference between the two means is Cohens’s d = .80, the proposed strategy is to set your target MoE at f = .40, which means that your target MoE is set at .40 standard deviations. If you plan for this value of target MoE with 80% assurance, the recommended sample size is n = 55 participants per group. These results are guaranteed to be true, if it is known for a fact that Cohen’s d is .80 and all statistical assumptions apply.
But it is generally not known for a fact that Cohen’s d has a particular value and so we need to answer a non-trivial question: what effect size can we reasonably expect? And, how can we have assurance that the MoE will not exceed half the unknown true effect size? One of the many options we have for answering this question is to conduct a pilot study, estimate the plausible values of the effect size and use these values for sample size planning. I will describe a strategy that basically mirrors the sample size planning for power approach described by Anderson, Kelley, and Maxwell (2017).
The procedure is as follows. In order to plan with approximately 80% assurance, estimate on the basis of your pilot the 80% confidence interval for the population effect size and use half the value of the lower limit for sample size planning with 90% assurance. This will give you 81% assurance that assurance MoE is no larger than half the unknown true effect size.
The logic of planning with assurance, with assurance
There are two “problems” we need to consider when estimating the true effect size. The first problem is that there is at least 50% probability of obtaining an overestimate of the true effect size. If that happens, and we take the point estimate of the effect size as input for sample size planning, what we “believe” to be a sample size sufficient for 80% assurance will be a sample size that has less than 80% assurance at least 50% of the times. So, using the point estimate gives assurance MoE for the unknown effect size with less than 50% assurance.
To make it more concrete: suppose the true effect equals .80, and we use n = 25 participants in both groups of the pilot study, the probability is approximately 50% that the point estimate is above .80. This implies, of course, that we will plan for a value of f > .40, approximately 50% of the times, and so the sample we get will only give us 80% assurance 50% of the times.
The second problem is that the small sample sizes we normally use for pilot studies may give highly imprecise estimates. For instance, with n = 25 participants per group, the expected MoE is f = 0.5687. So, even if we accept 50% assurance, it is highly likely that the point estimate is rather imprecise.
Since we are considering a pilot study, one of the obvious solutions, increasing the sample size so that expected MoE is likely to be small, is not really an option. But what we can do is to use an estimate that is unlikely to be an overestimate of the true effect size. In particular, we can use as our estimate the lower limit of a confidence interval for the effect size.
Let me explain, by considering the 80% CI of the effect size estimate. From basic theory it follows that the “true” value of the effect size will be smaller than the lower limit of the 80% confidence interval with probability equal to 10%. That is, if we calculate a huge number of 80% confidence intervals, each time on the basis of new random samples from the population, the true value of the effect size will be below the lower limit in 10% of the cases. This also means that the lower limit of the interval has 90% probability to not overestimate the true effect size.
This means that if we take the lower limit of the 80% CI of the pilot estimate as input for our sample size calculations, and if we plan with assurance of .90, we will have 90%*90% = 81% assurance that using the sample size we get from our calculations will have MoE no larger than half the true effect size. (Note that for 80% CI’s with negative limits you should choose the upper limit).
Sample Size planning based on a pilot study
Student of mine recently did a pilot study. This was a pilot for an experiment investigating the size of the effect of fluency of delivery of a spoken message in a video on Comprehensibility, Persuasiveness and viewers’ Appreciation of the video. The pilot study used two groups of size n = 10, one group watched the fluent video (without ‘eh’) and the other group watched the disfluent video where the speaker used ‘eh’ a lot. The dependent variables were measured on 7-point scales.
Let’s look at the results for the Appreciation variable. The (biased) estimate of Cohen’s d (based on the pooled standard deviation) equals 1.09, 80% CI [0.46, 1.69] (I’ve calculated this using the ci.smd function from the MBESS-package. According to the rules-of-thumb for interpreting Cohen’s d, this can be considered a large effect. (For communication effect studies it can be considered an insanely large effect). However, the CI shows the large imprecision of the result, which is of course what we can expect with sample sizes of n = 10. (Average MoE equals f = 0.95, and according to my rules-of-thumb that is well below what I consider to be borderline precise).
If we use the lower limit of the interval (d = 0.46), sample size planning with 90% assurance for half that effect (f = 0.23) gives us a sample size equal to n = 162. (Technical note: I planned for the half-width of the standardized CI of the unstandardized effect size, not for the CI of the standardized effect size; I used my Shiny App for planning assuming an independent groups design with two groups). As explained, since we used the lower limit of the 80% CI of the pilot and used 90% assurance in planning the sample size, the assurance that MoE will not exceed half the unknown true effect size equals 81%.










![\[\hat{\sigma_\psi}= \sqrt{\sum{c_i^2MS_e/n_i}},\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-e711016f1b800409ee4d1632159091d7_l3.png "Rendered by QuickLaTeX.com")
 is the contrast weight for the i-th condition mean, and
is the contrast weight for the i-th condition mean, and  the number of observations (in our example participants) in treatment condition i. Note that
the number of observations (in our example participants) in treatment condition i. Note that  is the variance of treatment mean i, the square root of which gives the familiar standard error of the mean.
is the variance of treatment mean i, the square root of which gives the familiar standard error of the mean.![\[MOE = t_{.975}(df_e)\sqrt{\sum{c_i^2MS_e/n_i}}=t_{.975}(df_e)\sqrt{4MS_e/n_i} = 2t_{.975}(df_e)\sqrt{MS_e/n_i}.\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-c566353662177824c69974b4d59785d4_l3.png "Rendered by QuickLaTeX.com")
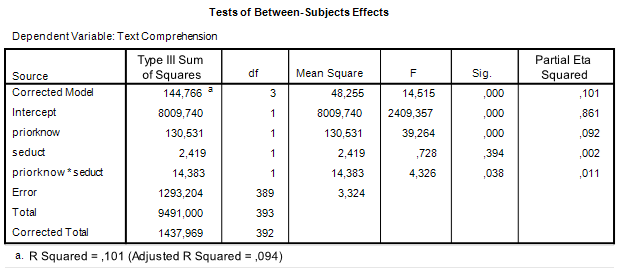
 , and the true value of Mean Square Error is 3.324, then MOE for the contrast estimate equals
, and the true value of Mean Square Error is 3.324, then MOE for the contrast estimate equals![\[MOE = 2*t_{.975}(396)*\sqrt{3.324/100} = 0.7071\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-98e408fbb1899034420a41dc86f58115_l3.png "Rendered by QuickLaTeX.com")
![\[MOE = 2*t_{.975}(df_e)\sqrt{(MS_w / n_i)},\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-1984a751953fc6b0698d72e7bf2c550b_l3.png "Rendered by QuickLaTeX.com")
 , since we are considering the 2×2 design.
, since we are considering the 2×2 design.![\[0.4558 = 2*t_{.975}(4(n_i - 1)\sqrt{(MS_w / n_i)},\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-9a775e47b691309421ea2f9d94c016c2_l3.png "Rendered by QuickLaTeX.com")
![\[MOE_{\gamma} = 2*t_{.975}(df)*\sqrt{MS_w/n_i*\chi^2_{\gamma}(df)/df},\]](https://small-s.science/wp-content/ql-cache/quicklatex.com-f5945fe8ef0dad8f2bf28d70a7553fae_l3.png "Rendered by QuickLaTeX.com")
 is the assurance expressed in a probability between 0 and 1.
is the assurance expressed in a probability between 0 and 1.